Free text has to become destination, dates, children, pets, travel mode, and planning constraints.
Hybrid AI / live production / family travel
SproutRoute
A hybrid AI travel planner that separates what AI should generate from what must be verified, deterministic, or cached. The product decision was to make AI write connective tissue, not facts. I defined the product, designed the system architecture, and operate the web app in production.
Live production productMCP path implemented
- Stack
- Railway + Supabase
- AI
- Gemini + Places
- Quality
- 350+ tests
- Core choice
- Facts before prose
- Decision
- Let verified APIs and deterministic rules own facts; use models for planning and connective prose.
- Why
- Weather, places, safety, and family packing require provenance and predictable failure handling.
- Result
- A production web product with 350+ tests and an additive four-agent MCP path with handoff traces.
What this provesAI boundaries
Trustworthy AI planning starts with product boundaries.
This case shows product judgment under AI uncertainty: which user promises need deterministic control, which experiences can be generative, and how latency, cost, provenance, and trust shape the product architecture.
ComplexityBoundaries
The hard parts were in the boundaries.
Users type fuzzy travel intent. The system has to extract constraints, route across external APIs, separate factual data from generative text, keep family-safety information reliable, and avoid turning every trip plan into a slow serial dependency chain.
Weather, geocoding, places, policy, AI, and persistence layers all fail differently.
Weather, safety, places, and packing must not be hallucinated by itinerary prose.
Moving from 8-12 seconds required parallelization, caching, and hot-path discipline.
ScreensShipped flow
The artifacts should show the shipped flow, not a decorative mockup.






ArchitectureEvolution
Three architectural stages, each driven by a production problem.
Fast to ship, but slow, expensive, and unreliable for packing and safety.
Moved packing to rules and routed models by task to improve reliability.
Stored verified attractions with freshness scoring so one trip improves the next.
Verified data feeds the AI planner; AI writes connective tissue, not facts.
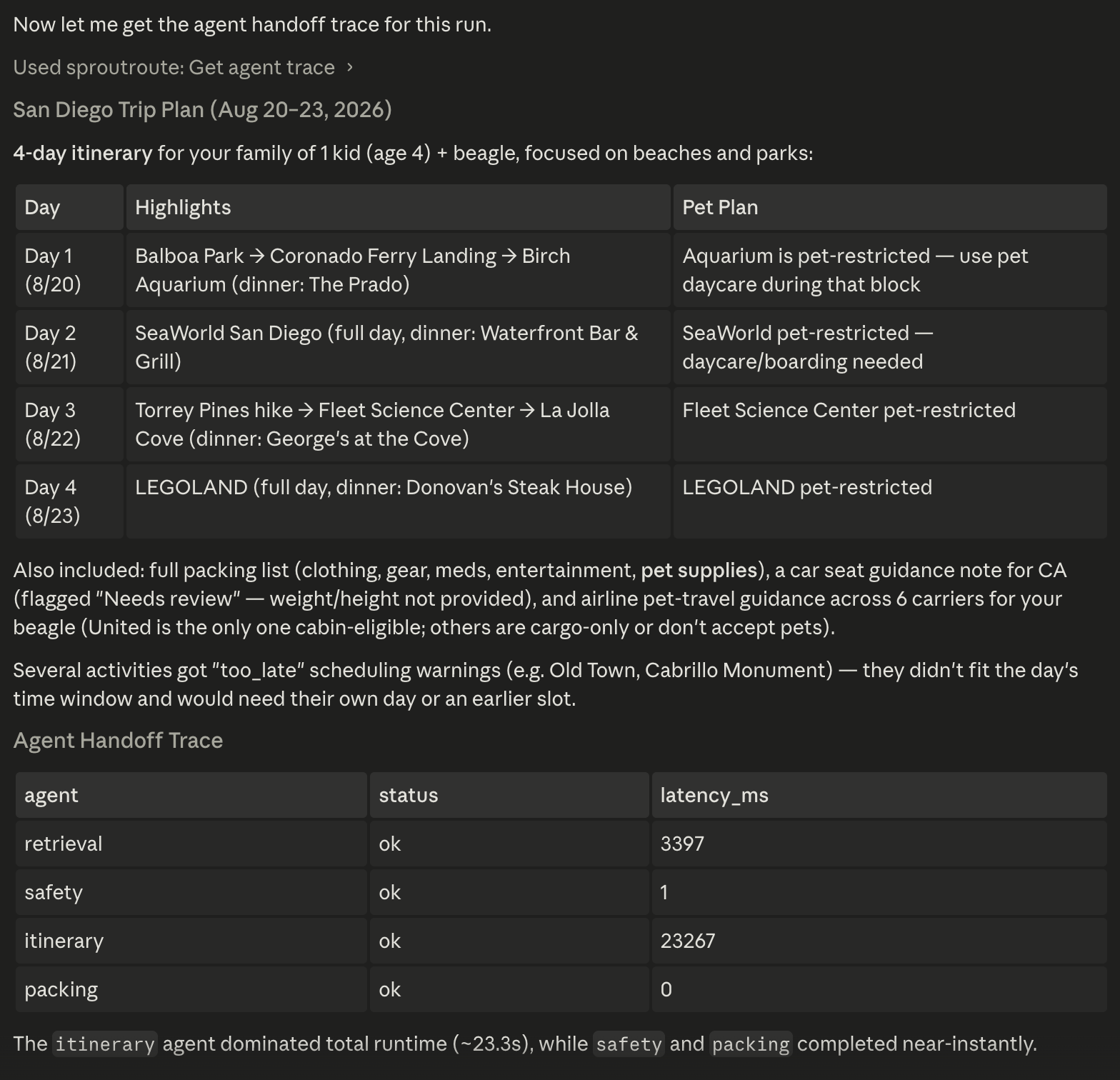
Implemented a LangGraph orchestrator with four specialist agents and a hosted MCP server without replacing the stable web route. The path validates delegation, partial results, trace privacy, and tool contracts for the enterprise agent runtime.




DecisionsJudgment
The page should make the tradeoffs inspectable.
Family travel packing is constraint-based. Reliability beats novelty.
Different steps need different cost, latency, and reasoning profiles.
Freshness scoring narrows the search space and improves repeat plans.
Weather, places, and safety data need provenance before prose.